Symmetric signing algorithms like HMAC can be used to securely sign access tokens, but with two extremely important caveats:
- The secret key must be strong enough to avoid simple brute-force attacks (high entropy, sufficiently long, and randomly generated)
- The secret key must NEVER be leaked
Unfortunately for the first point, hashcat received its public release in 2009.
Since then, advances in GPU hardware and frameworks like NVIDIA CUDA have turned tools such as hashcat into increasingly effective brute-force engines, capable of breaking secrets that were once considered safe.
Still, given a sufficiently long and random key, this is not a concern with HMAC-SHA256.
The second issue is a much larger problem for symmetric signing approaches like HMAC. Since the signing key is also used for validation, it must be provided to the server, not just the token issuer. And this secret key must never be accidentally exposed in deployment pipelines, configuration files, or logs. This increased attack surface is a massive risk!
What’s worse, a compromised signing key gives no indication to server owners. With no key rotation, a stolen key can be used to sign tokens with ANY level of access indefinitely. Attackers can use this key to quietly read or corrupt sensitive data without revealing their access. For any AIStore deployments that are not carefully gated in a protected environment, this could spell disaster.
With the 4.3 and subsequent 4.4 releases, AIStore AuthN now supports RSA signing keys and OIDC Issuer Discovery -- two essential features to mitigate the risk of this total security collapse.
Table of Contents
- RSA JWT Signing
- OIDC Issuer Discovery
- Complete Kubernetes Deployment
- Conclusion and Future Work
- References
RSA JWT Signing
Previously, AIStore AuthN relied on HS256, which uses HMAC-SHA256 with a shared secret key. This is a symmetric algorithm, where the same secret is used for both signing JWTs and validating them.
This meant the signing key was distributed and could potentially exist in files, K8s secrets, K8s Pod specs, or environment variables in the actual AIS deployment.
We needed to be able to distribute a key publicly without exposing the ability to sign new tokens. That’s where asymmetric RSA signing key pairs come into the picture. With RSA, the private key never leaves the AuthN service. JWT signatures are validated only by a public key that cannot be used to sign new tokens.
AuthN also now supports encrypting the private key locally with a passphrase so it’s never unprotected on disk even within the service.
See RSA Signing in the AuthN docs for more details.
OIDC Issuer Discovery
Static Key Distribution
Even with the improved security of RSA keys, relying on static key distribution presents challenges.
First, this still doesn’t fully address the issue of compromised keys. Private key leaks are less likely, as they are never distributed, but we still risk silent exposure. Without key rotation, a compromised private key can be used to mint fraudulent JWTs indefinitely. And by using a static public key in AIS config, we can’t simply rotate the validation key in AIS without invalidating all existing tokens.
The static config also adds friction to deployment, since AuthN generates the key pair. Any AIS cluster deployment would need to inject the generated public key into its config.
Trusted Issuers
OIDC issuer lookup solves all of this by validating JWTs with a cached set of keys from trusted issuers.
Instead of checking a JWT signature with a static public key, AIS uses the iss and kid claims from the JWT to look up the associated public key.
AIS itself has supported the concept of OIDC issuer discovery since version 4.1, but this was restricted to 3rd-party JWT issuers, which needed additional configuration to support the custom JWT format for AIS access.
This update brings that functionality to the native AIStore AuthN service, offering much better security and simplified deployment compared to the previous approach of symmetric, static signing keys.
OIDC in AuthN
AuthN does NOT fully implement the OIDC spec.
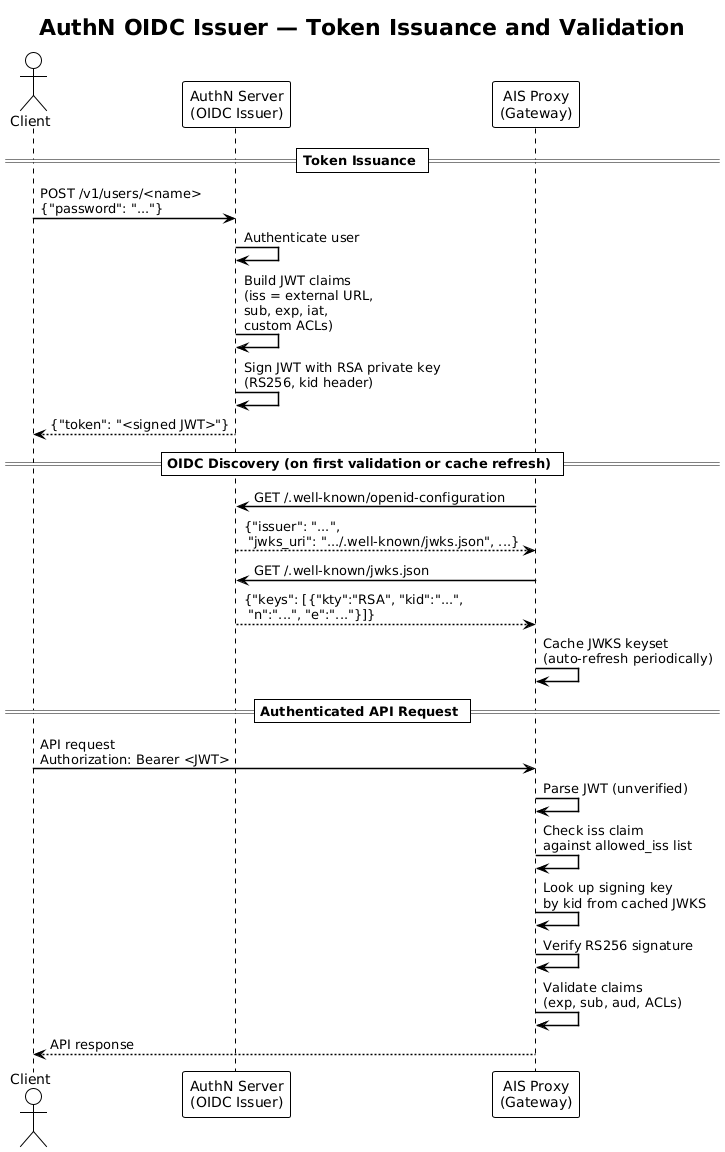
It simply exposes the path /.well-known/openid-configuration, which responds with a “discovery document” containing jwks_uri.
That jwks_uri path then returns the complete set of valid public JSON Web Keys (JWK).
A JWK is a generic JSON container for different key types.
In the case of AuthN, it represents an encoded RSA public key with some extra metadata.
This JWK set (JWKS) is then cached on the AIStore proxies, where the keys are used to validate JWT signatures.
Below is a diagram showing the full flow; see the AuthN docs for more implementation details.
Drawbacks and Limitations
One disadvantage is that previously, AIS had no dependency on the availability of the AuthN service. Now, AIS expects AuthN to be reachable for updating the local cache of key sets on a regular basis, increasing the requirement for AuthN reliability. Deploying in K8s simplifies this, but multi-replica support for AuthN requires ongoing work (see future work).
However, AIS will not need to query AuthN on every request, and in fact caches the key sets intelligently thanks to the JWX library.
Note: AIS currently only refreshes its cached key sets for a specific issuer on proxy restart. This is a known deficiency that limits the usability of key rotation and will be fixed in a future release. See the signing key rotation section below.
Complete Kubernetes Deployment
With RSA signing and OIDC discovery, the signing key is no longer shared, keys can be rotated without touching AIS config, and AIStore and AuthN can be deployed in any order without pre-distributing keys.
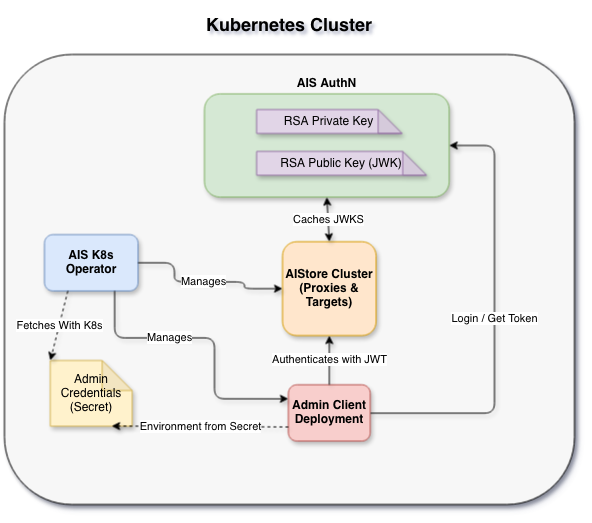
To demonstrate, we’ll show a local AIS cluster deployed in K8s alongside AuthN, runnable in K8s KinD via a single script.
See the full deployment scripts on the ais-k8s repo.
Running the Deployment
See the guide in ais-k8s for full details. First, you’ll need a few prerequisites:
Next, to create the local deployment, clone ais-k8s and navigate to local.
Then run ./test-cluster.sh --auth.
That’s it! The script will bootstrap a local K8s cluster with all dependencies and an entire stack for AIS: K8s operator, AIS cluster, AIS AuthN, and an admin client deployment.
Once deployed, run the following to drop into a shell on the admin client pod inside the cluster:
kubectl exec -it -n ais deploy/ais-client -- /bin/bash
Initially, the AIS CLI won’t have access because AIS is enforcing authentication:
root@ais-client-7d869f99bf-dp76b:/# ais ls
Error: token required
This pod is pre-configured with environment variables for accessing the AuthN service.
Run ais auth login $AIS_AUTHN_USERNAME -p $AIS_AUTHN_PASSWORD to fetch a token.
Now the client in this pod has full admin access to the local cluster.
root@ais-client-7d869f99bf-dp76b:/# ais auth login $AIS_AUTHN_USERNAME -p $AIS_AUTHN_PASSWORD
Logged in (/root/.config/ais/cli/auth.token)
# Successful request
root@ais-client-7d869f99bf-dp76b:/# ais ls
No buckets in the cluster.
Below is a simplified diagram showing the entire setup:
AuthN Config
In recent versions of AuthN, RSA is the default signing method and will auto-generate a key pair on initial startup.
The relevant configuration for enabling OIDC lookup in the AuthN local helm environment is net.ExternalURL:
net:
externalURL: "https://ais-authn.ais.svc.cluster.local:52001"
This tells the AuthN service what to use when building the jwks_uri in the openid-configuration response.
The URL that clients can use to access the service depends on the deployment, so it must be configured in advance.
AIS Config
Because the AIS cluster runs in the same local deployment, we can use the K8s service DNS to access AuthN directly.
In the local-auth helm values for AIS, we set configToUpdate to update the AIS internal configuration to trust JWTs signed by the given allowed issuer.
The auth section configures how the operator and admin clients connect and provision an admin token by using credentials from a K8s secret.
# Configure AIS to trust JWTs issued by the local AuthN issuer
configToUpdate:
auth:
enabled: true
# Instead of signature.key, we configure a list of issuers that we trust
oidc:
allowed_iss: ["https://ais-authn.ais.svc.cluster.local:52001"]
# Client AuthN API config used by operator and admin client
auth:
serviceURL: "https://ais-authn.ais.svc.cluster.local:52001"
# Currently, AuthN only supports username and password login to fetch tokens
usernamePassword:
secretName: ais-authn-su-creds
Conclusion and Future Work
Moving towards RSA signing and OIDC issuer lookup is important for AuthN, but there’s more we want to build:
Signing Key Rotation
Issuer lookup supports multiple active signing keys, which in theory allows for seamless rotation.
Currently, AuthN keys can be rotated manually via ais auth rotate-key.
However, AIStore version 4.4 won’t accept tokens signed by the new keys until the cached keyset is refreshed.
This refresh is only triggered by the previous JWK’s expiry date (currently unset by AuthN) or by a proxy restart.
Once live rotation is fully supported on the AIStore side, automated signing key rotation for AuthN is a natural progression. Configurable intervals for automated rotation would eliminate the manual step and reduce the window of exposure if a key is compromised.
Multi-replica Support
Since AIS now actively queries AuthN for key sets, a single-replica AuthN becomes a potential availability bottleneck. Supporting multiple replicas would bring AuthN to production-grade availability.
This is a non-trivial development that requires more than a simple scale-up. AuthN currently uses BuntDB as its underlying storage. Support for distributed DBs will be required for multi-replica access. Signing keys must also be distributed and synchronized between instances to support consistency between multiple signers.
Service Account Authentication
A current limitation is that the AIS operator requires K8s secrets for admin credentials to manage AuthN-enabled clusters. One proposed alternative is to support AuthN token provisioning via a K8s projected service account token. This moves the access control used for the operator and admin client deployments to K8s RBAC and away from static credentials.
Follow our progress on the main AIStore repo or try out the local deployment yourself!
References
AIStore Authentication
- AuthN Documentation
- AIS Auth Validation
- AIS Auth CLI
- ais-k8s Local Deployment
- AuthN in K8s docs
- AuthN in K8s Helm
Standards and Specs
- OpenID Connect Core 1.0
- OpenID Connect Discovery 1.0
- HMAC (RFC 2104)
- JSON Web Token (RFC 7519)
- JSON Web Key (RFC 7517)
- JSON Web Algorithms (RFC 7518) -- RSA
Libraries and Tools
- AIStore JWK caching library: lestrrat-go/jwx
- Kubernetes in Docker (KinD)
- AuthN storage: BuntDB
General
]]>
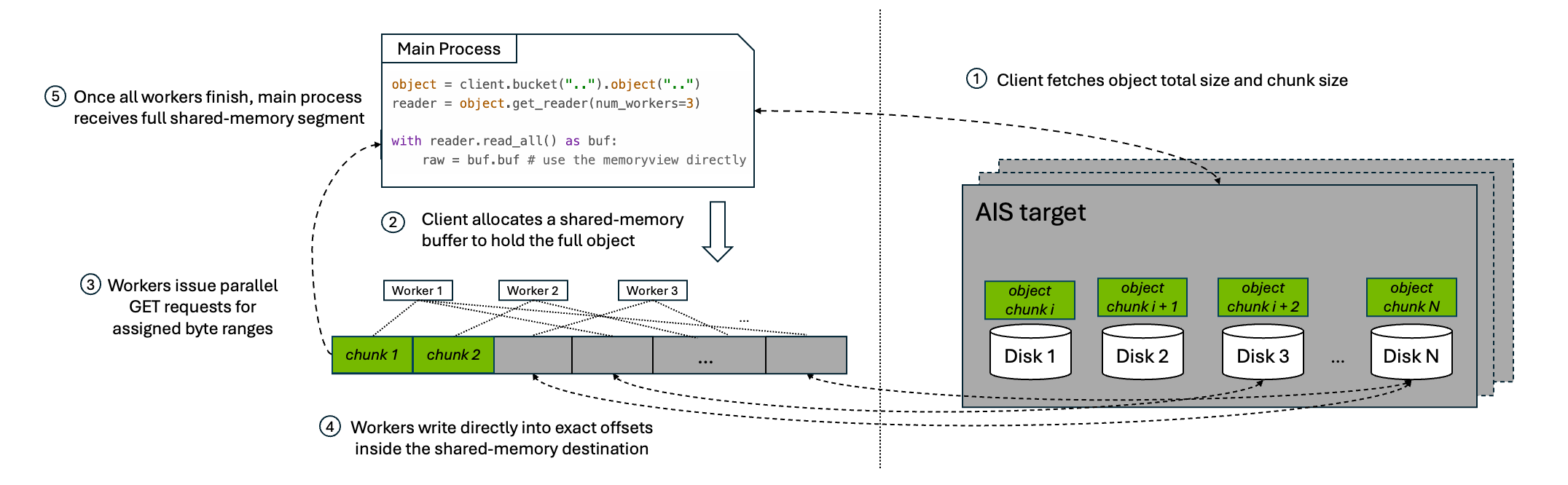
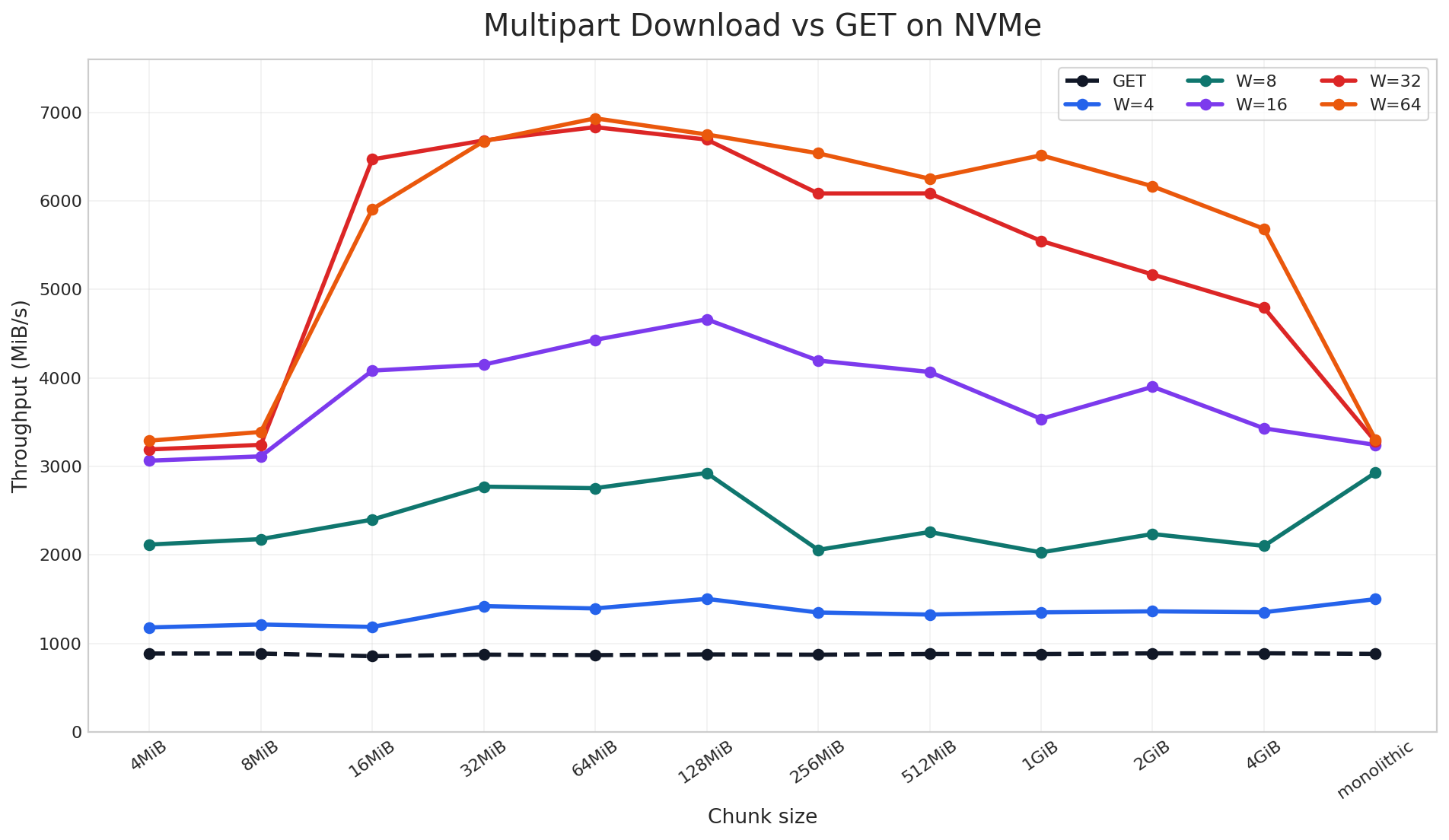
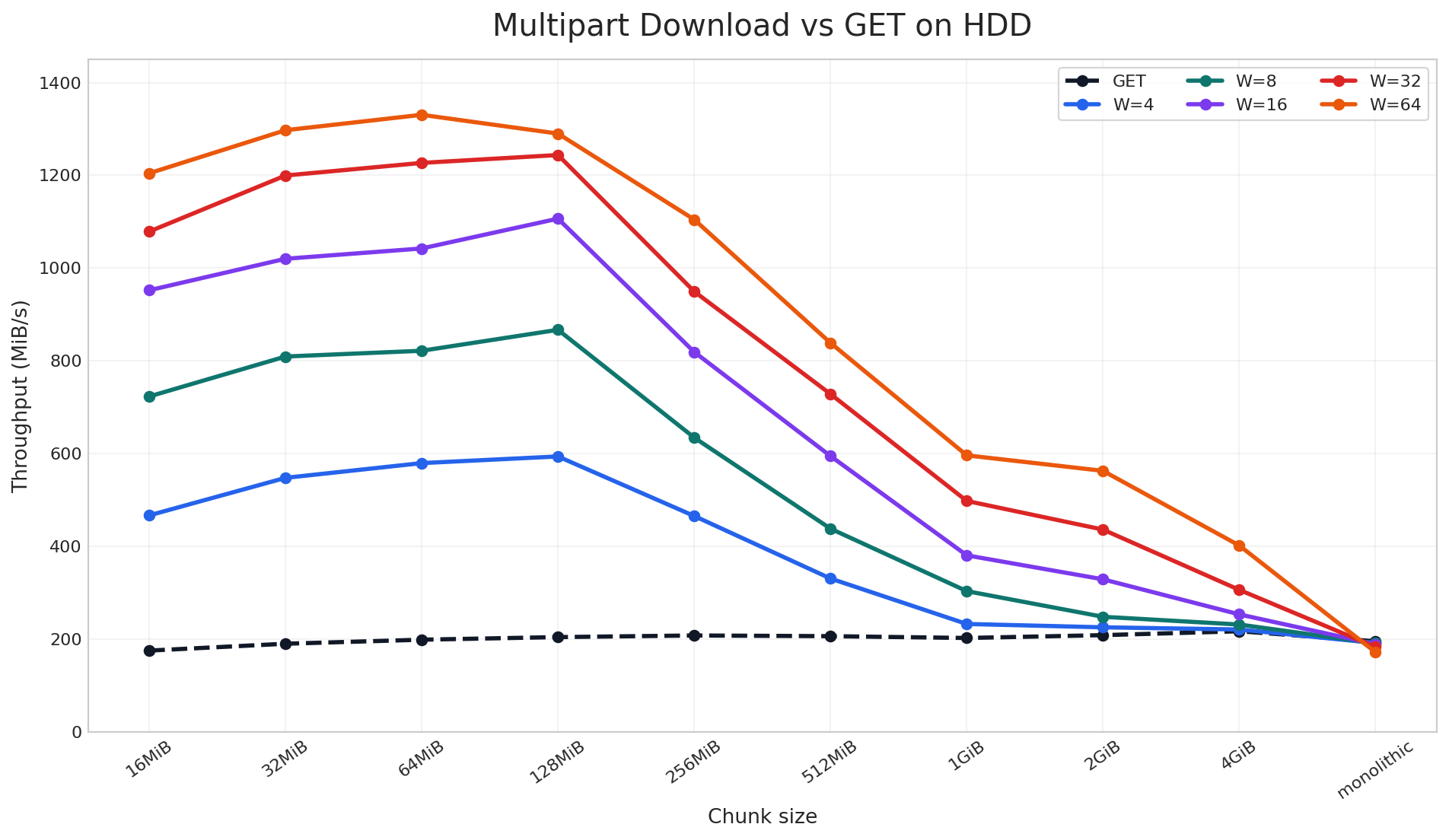
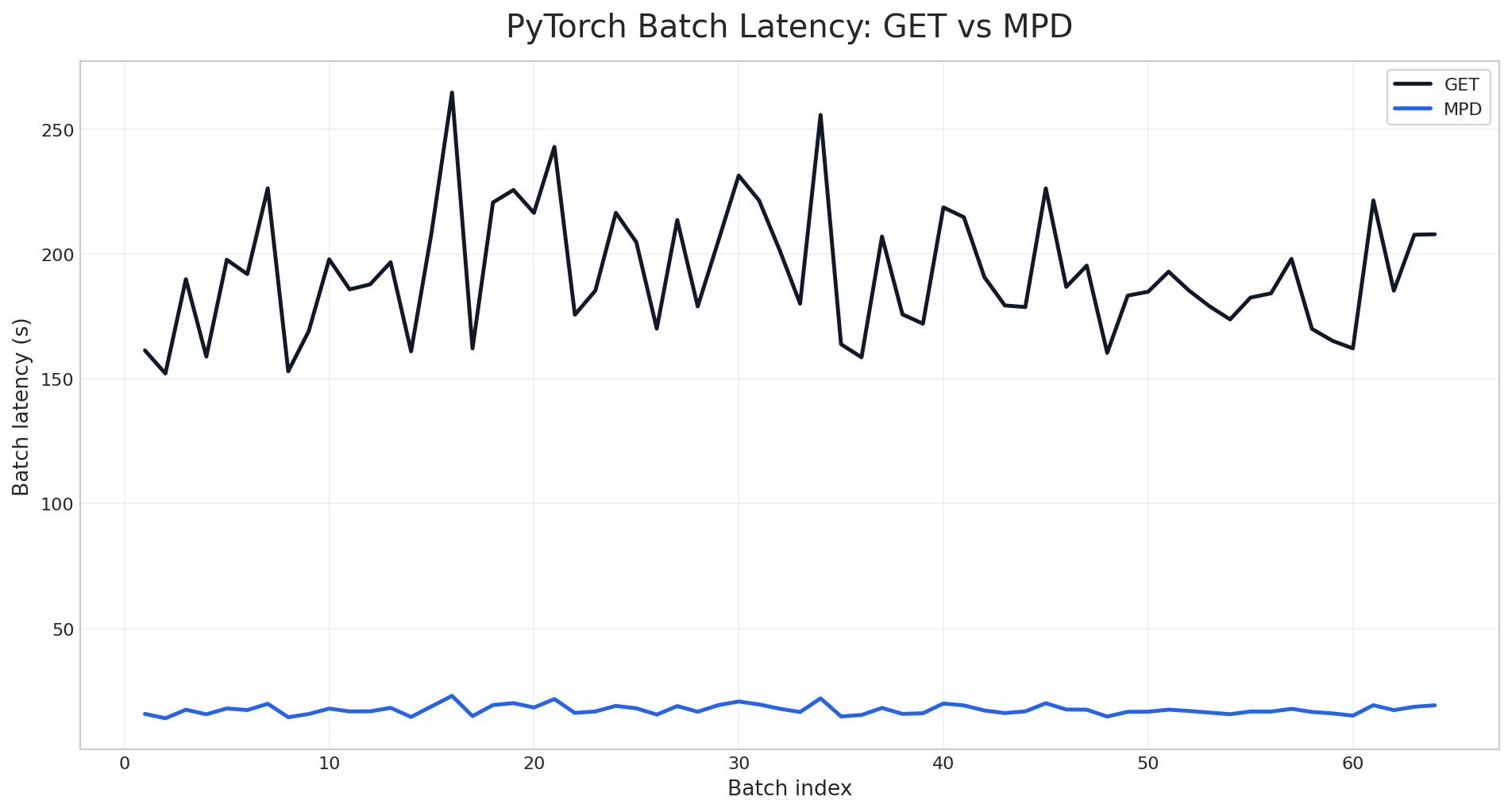
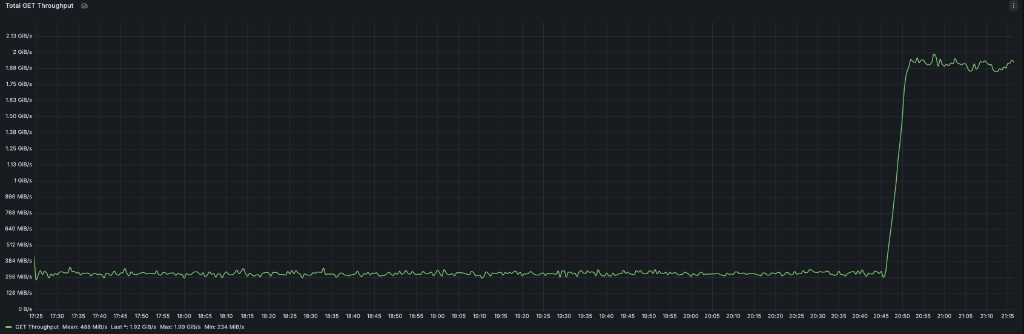
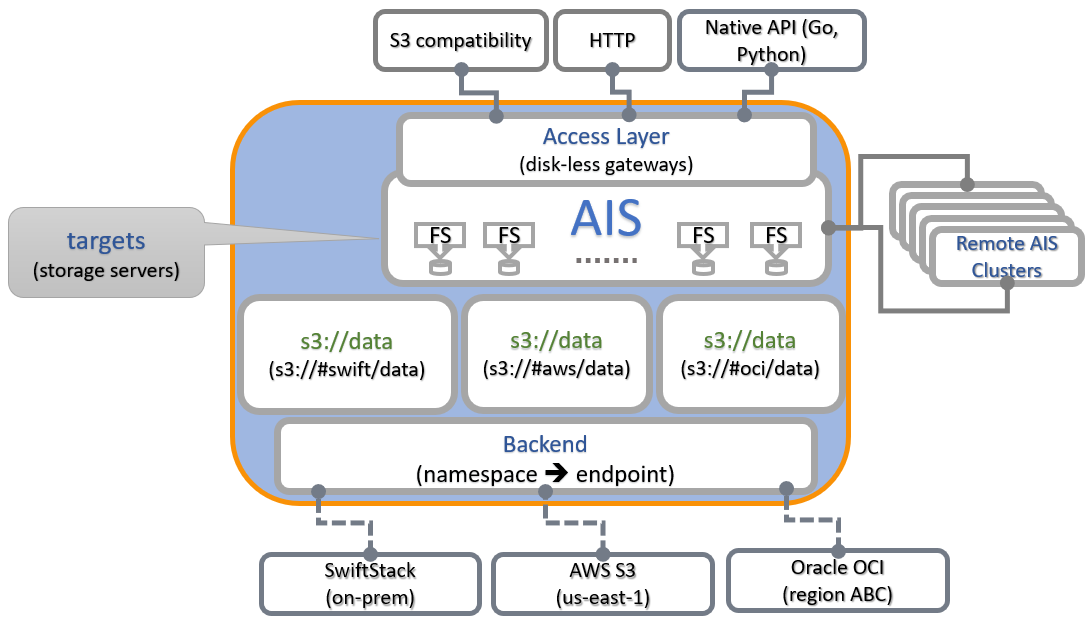
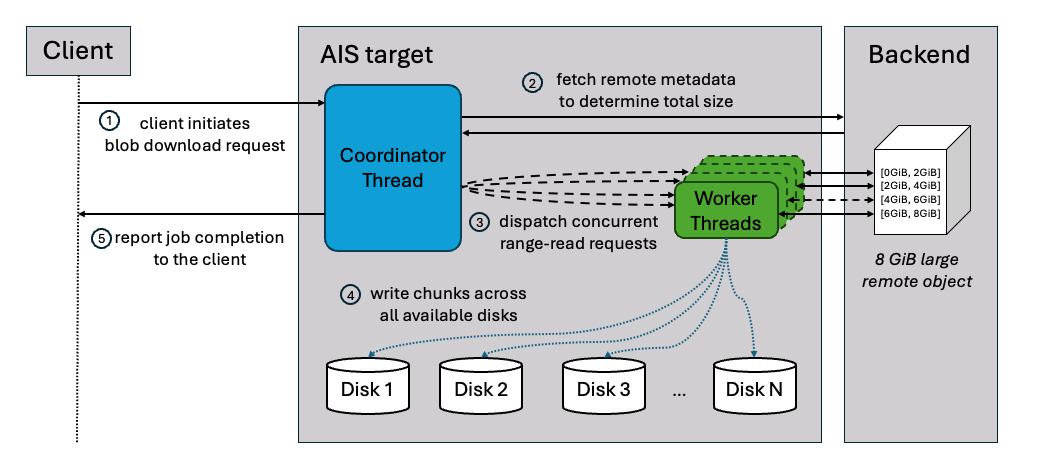
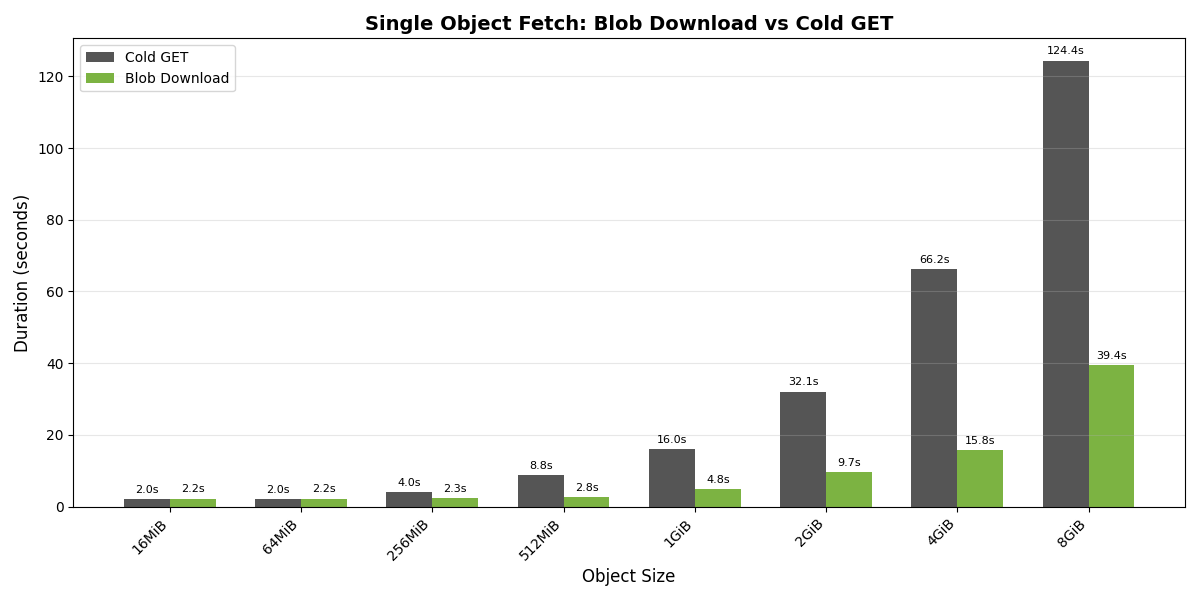
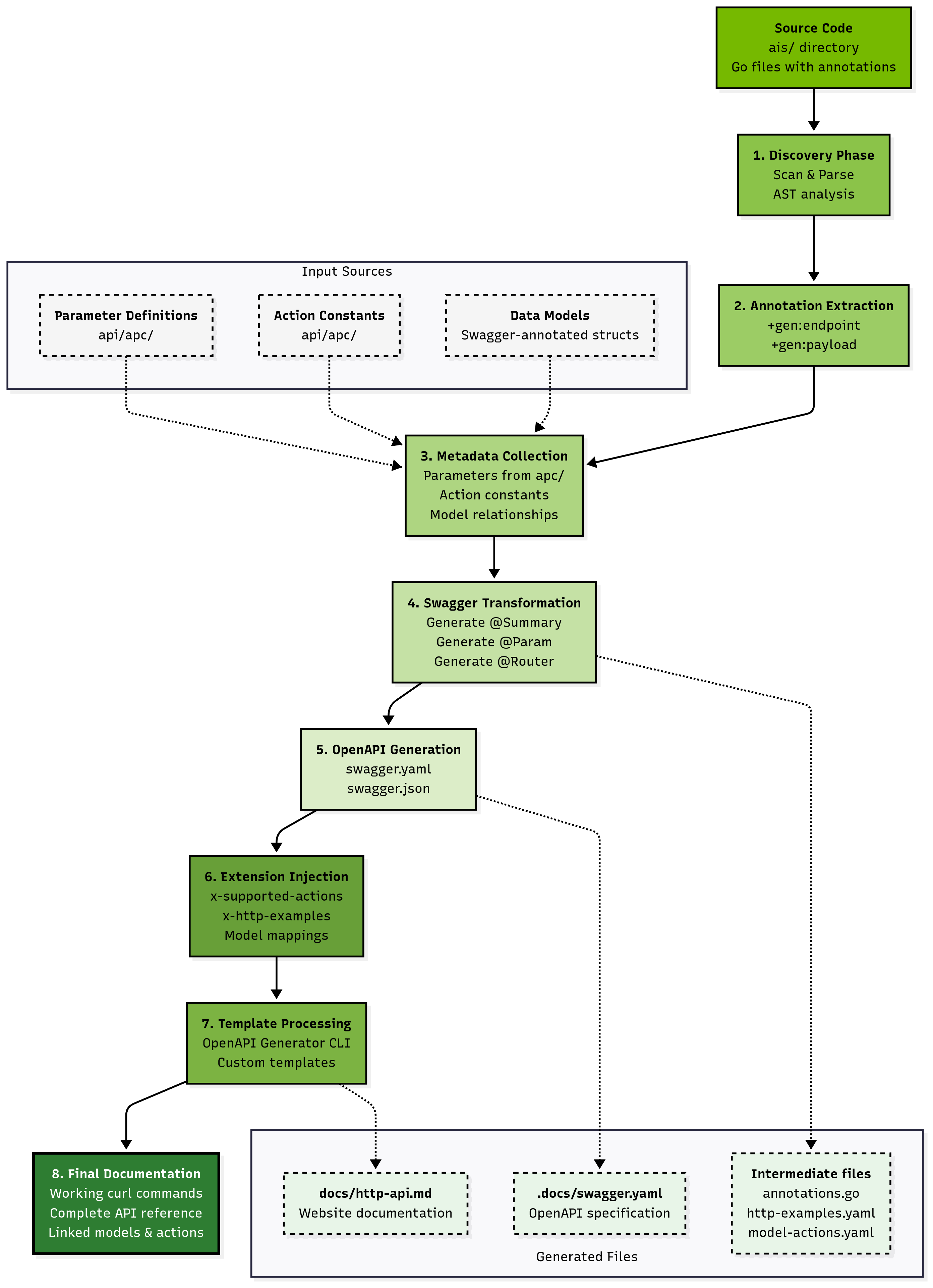 Figure: GenDocs multi-phase pipeline transforming source code annotations into comprehensive API documentation
Figure: GenDocs multi-phase pipeline transforming source code annotations into comprehensive API documentation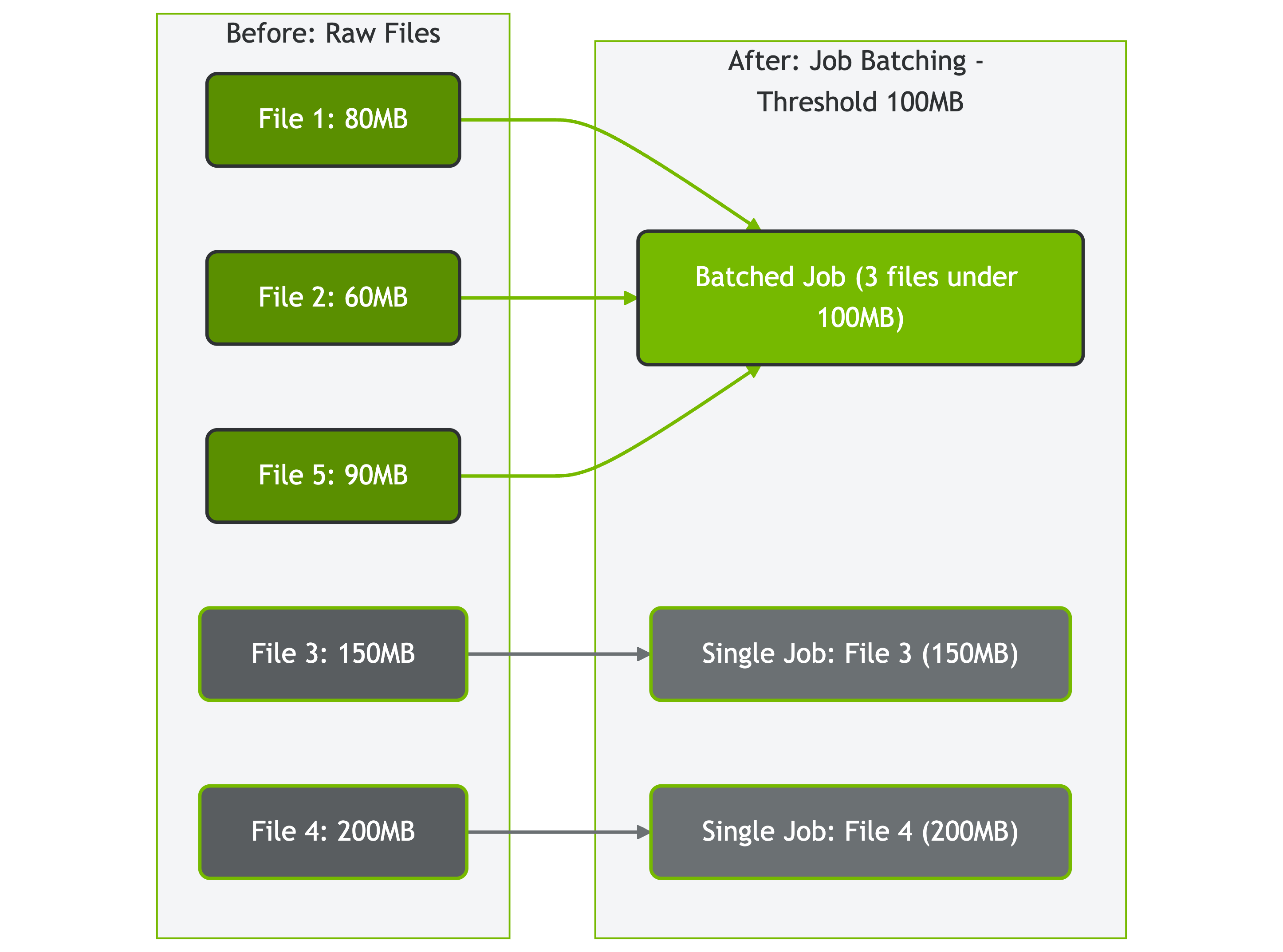 Figure: How AIStore batches files based on size threshold (100MB in this example)
Figure: How AIStore batches files based on size threshold (100MB in this example)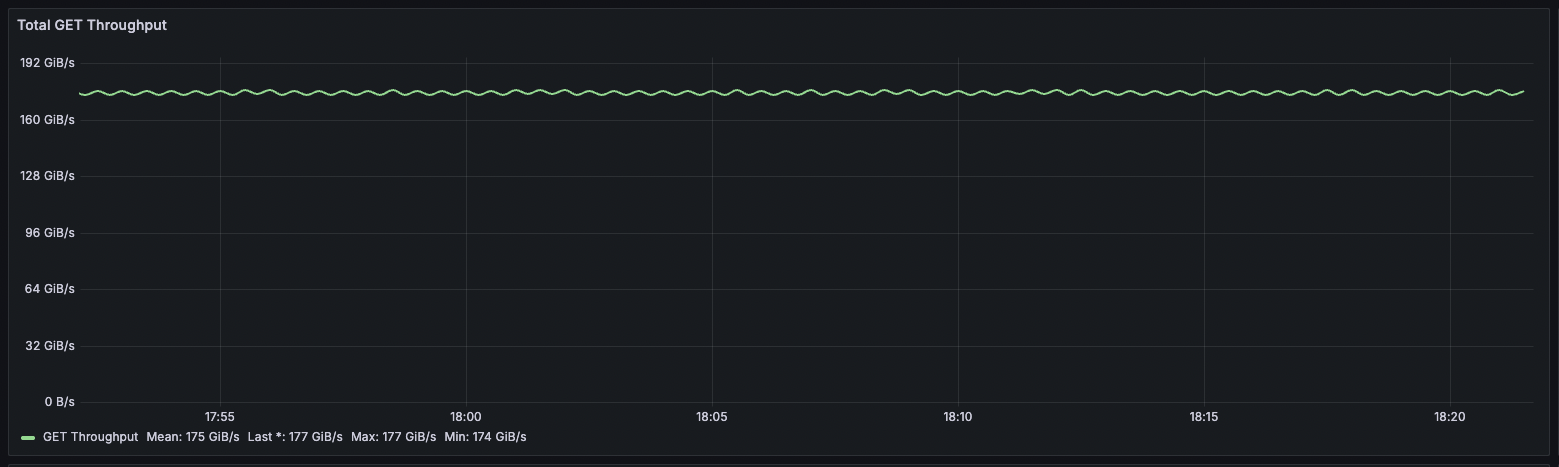 Fig. 1. Aggregated cluster throughput.
Fig. 1. Aggregated cluster throughput.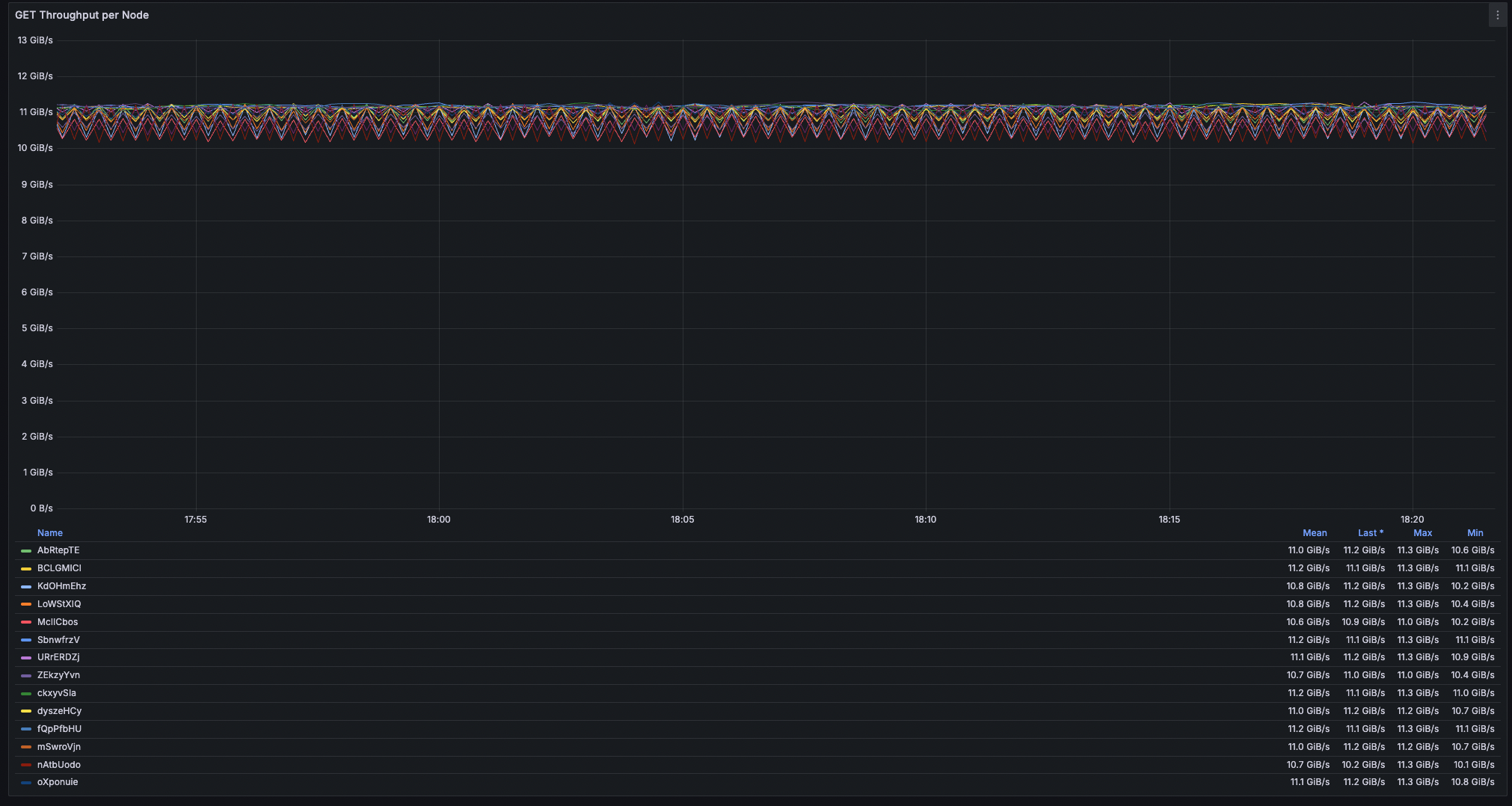 Fig. 2. Node throughput (16 nodes).
Fig. 2. Node throughput (16 nodes).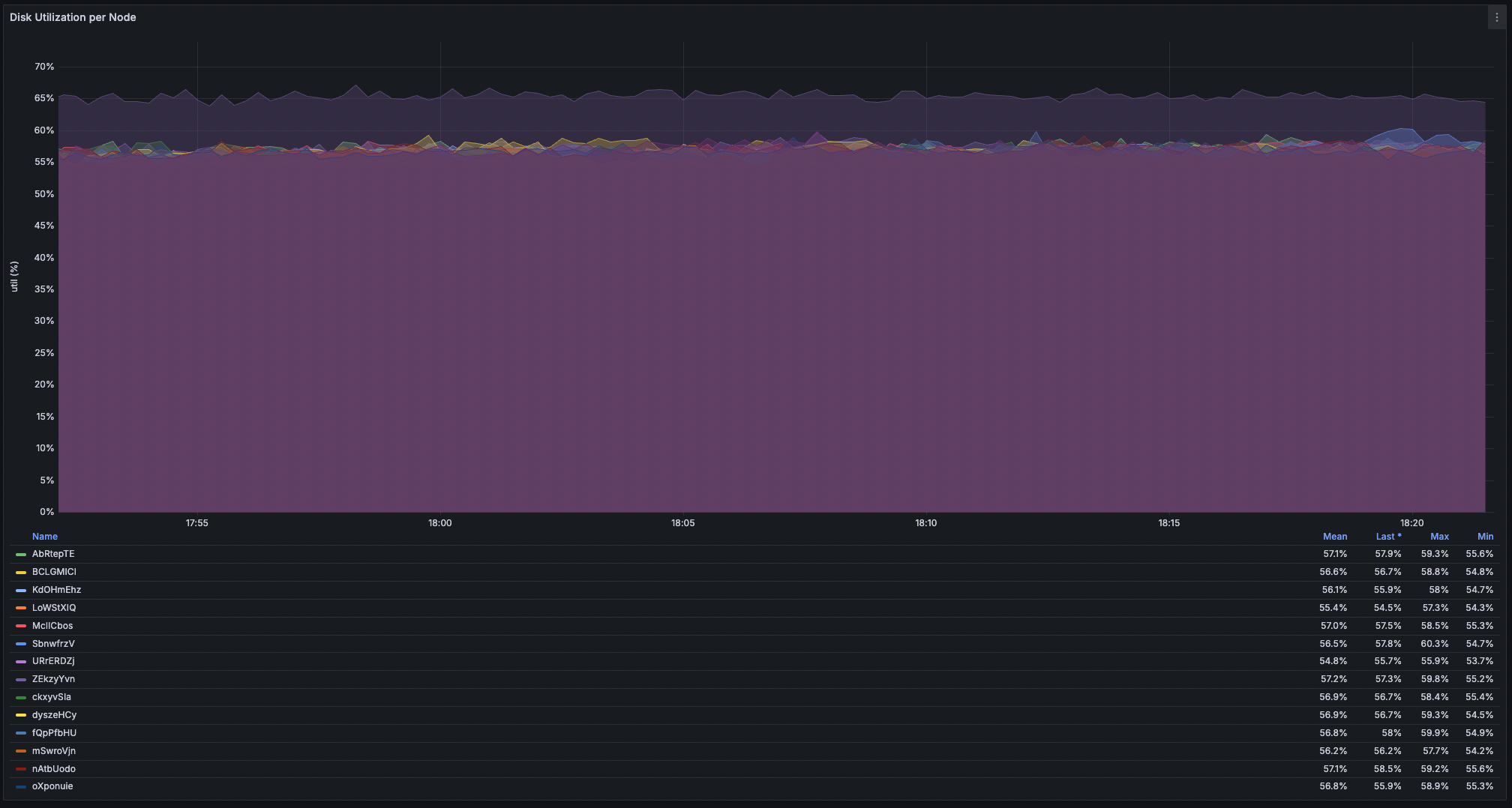 Fig. 3. Disk (min, avg, max) utilizations (16 nodes).
Fig. 3. Disk (min, avg, max) utilizations (16 nodes).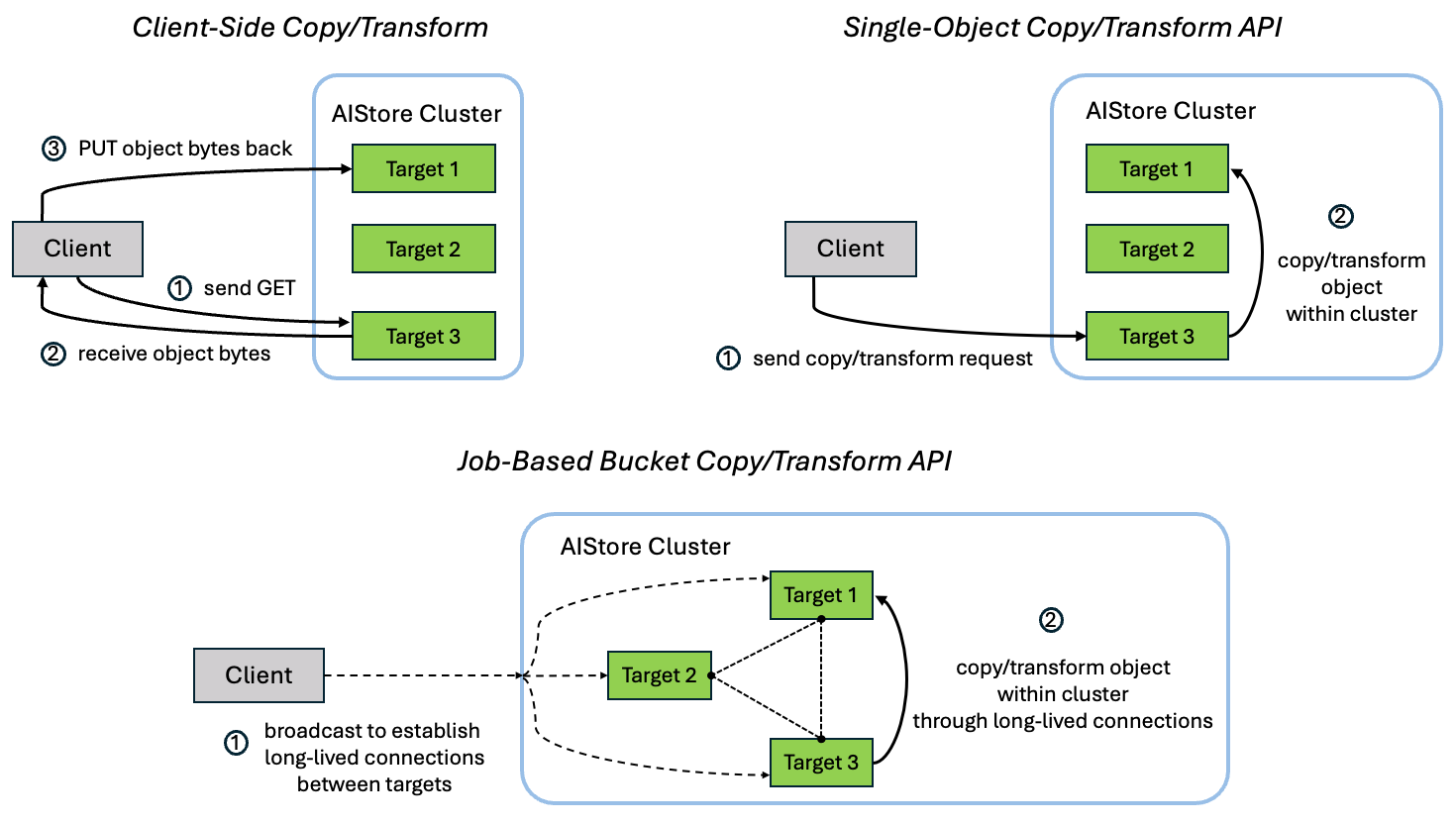
{kind=link}